출처 :
http://blog.naver.com/wondo21c/30043174174
Visual Studio 2005 프로젝트 속성 ->구성속성을 보면
문자 집합으로 2가지를 사용할 수 있다.
1. 멀티바이트 문자 집합
2. 유니코드 문자 집합
아스키코드는 모든 문자 하나가 1byte를 차지한다.
하지만, 아스키 문자 코드 만으로는 한글이나 일어 등의 다른 문자를 표시할 수 없다.
그래서 아스키 문자 코드에다가 다른 문자(2byte)들을 포함한 문자 집합이 멀티바이트 문자 집합이다.
정확히는 모르겠지만, 한 문자가 2byte를 넘는 문자도 존재할 것이다.
그래서 용어 자체가 멀티바이트 문자 집합이 아닐까 생각한다.
그런데 멀티바이트 문자 집합은 특정 문자 집합마다의 코드페이지가 존재한다.
예를 들어, 같은 코드 번호 일지라도 한글 코드 페이지로 해석하면 한글이 나오지만,
일어 코드 페이지로 해석하면 일어가 나온다.
그래서 이상하게 깨지는 문자 등을 우리는 목격할 수 있다.
이것의 방안으로 탄생한 것이 유니코드!
유니코드는 아스키 문자 코드 뿐만 아니라, 한글, 일어 등등 어떠한 문자들을 총 망라하여
각 한 문자에 2byte씩으로 할당하여 만든 문자 집합이다.
그리하여 각각의 특정 문자는 고유의 유니코드값을 가진다.
우리의 문제는 코딩 시에, 어떻게 해야 하는가!
너무나도 초보인 나는 아직 ANSI 표준 문자열을 쓰는데도 익숙치 않다.
하지만 메모리를 다루는 프로그래머로써 1bit의 메모리라두 잘못된 경우에는
프로그램 전체를 뻑(Crash)하는 우려를 범하곤 한다.
나같은 게임 프로그래머로서는 게임 실컷 만들어 놓고, 유저들에게 버그 많다고 욕들어 먹는다. ^^;;
게임뿐만 아니라 어떤 프로그램도 요새는 세계화가 아닌가!
그래서 한글과 영어만으로는 완벽하다고 안심해서는 안된다.
대만어, 프랑스어 등등 어떠한 문자 앞에서도 굴하지 않아야 된다.
그렇다고 우리가 각각의 나라별로 게임을 개별적으로 만들어 줄 수는 없지 않은가!
그래서 소스 상에서 유연성이 필요한 것 같다.
일단, 나는 자주 쓰는 몇 개의 습관부터 고치고자 노력해야 겠다.
|
char |
TCHAR |
|
strcat_s() |
_tcscat_s() |
|
strcpy_s(), strncpy_s() |
_tcscpy_s() , _tcsncpy_s() |
|
strlen() |
_tcslen |
|
sprintf_s() |
_stprintf_s |
그리고 문자열을 바로 쓸 때,
"" 대신에 TEXT("")을 쓰자.
TEXT 매크로는 유니코드의 설정에 따라 상수의 타입을 달리 한다.
예를 들어 유니코드로 컴파일 할 경우, TEST("a")를 16bit(2byte) 문자로 인식하고,
아닐 경우, 8bit(1byte) ANSI 문자로 인식한다.
밑의 표는 인터넷에서 구한 것.
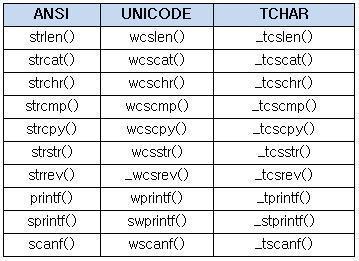
추가 :
char *, LPCSTR, TCHAR 차이
문자열을 처리하는 기본 자료형은 보통 char, wchar, TCHAR 를 사용한다.
char * 는 LPSTR 이며, (LP 는 Long Pointer)
const char * 는 LPCSTR 이다.
그럼 TCHAR 란?
한글을 포함한 다양한 나라의 독특한 언어 표현을 위해(영어제외) 최소 2바이트가 필요하다.
(영어는 1바이트)
MultiByte 를 사용하기도 하지만, 영어는 1바이트, 한글은 2바이트로 나눠지기 때문에
메모리 관리가 어려워 진다.
그래서 사용하는 것이 wchar 이다.
wchar 는 모든 문자를 2바이트로 구성한다.
(기존 자료형보다 메모리 2배 공간필요)
TCHAR 는 char 인지, wchar 인지 구별하지 않고 코딩 할 수 있게끔 해주기 위해 존재한다.
TCHAR 가 어떤건지에 대한 구별은 UNICODE 라는 precompile 상수를 이용해서 구분하며,
이는 project->settings 에 _DEBUG 등등이 선언되어 있는데 끝에 선언해 주면
TCHAR 는 wchar 로 변환해서 컴파일을 시도한다.
글로벌한 제품 개발을 위해서는 TCHAR 사용이 필수인듯 하다.
댓글1:
원래 영운은 1바이트잖아요.
그런데 한글이나 중국어 등 영문권이 아닌 제 3세계 문자를 표현하기 위해서는 2바이트가 필요하죠.
이를 위해서 멀티바이트를 사용하기도 하지만 멀티바이트는 어떤문자는 1바이트이고 어떤문자는 2바이트여서 메모리 관리가 어렵게 됩니다.
그래서 wchar 가 등장하는데 wchar 는 모든 문자(영문포함)가 2바이트로 구성이 되니까
당연히 wchar 는 일반 ascii 타입의 char 보다 메모리 공간이 2배 필요하게 되는거죠.
그럼 여기서 TCHAR 는?
그건 바로 acscii 타입의 일반 Char 또는 wchar 라는 의미예요.
TCHAR를 사용하면 char 인지 wchar 인지 구별하지 않고 그냥 코딩할수 있게 되죠.
댓글2:
한마디로 TCHAR 를 사용하고 컴파일러에 유니코드라고 알려주지 않으면 char로 동작하는거죠.
나중에 wchar로 사용하려면 컴파일러에 유니코드라고 해주면 소스코드는 손 안대도 되는거겠죠?
'컴퓨터 > C_Programing' 카테고리의 다른 글
| Visual Studio 2013 완전 제거하기 (setup blocked) (5) | 2016.03.05 |
|---|---|
| VC 에서 sourcesafe 연결 삭제 하기 (0) | 2016.02.02 |
| visual stdio 200x 단축키 모음 (0) | 2016.02.02 |
| Visual Studio C언어 디버그 모드 & 릴리즈 모드 (0) | 2016.02.02 |
| visual studio 2013 break at function 조건부 디버깅 (0) | 2016.01.17 |